NVR&XVR SDK架构介绍
1. 模块介绍¶
| 简称 | 全称 | 职责 |
|---|---|---|
| SYS | System | 实现MI系统初始化、内存管理、各个模块之间数据流的管理 |
| VDEC | Video Decoder | H264/H265 视频解码器 |
| JPD | Jpeg Decoder | Jpeg解码器 |
| SCL | Scaler | 缩放/裁剪/格式转换等功能 |
| VDISP | Vitrual Display | 软件拼图 |
| DISP | Display Engine | DISP对VDEC/SCL 处理单元输出的图像做硬件拼图,并连同AO输出音频信号一起编码成HDMI/VGA/CVBS 输出信号的单元 |
| VENC | Video Encoder | H264/H265/MotionJpeg编码器 |
| AI | Audio Input Interface | audio input采集单元 |
| AO | Audio Output Interface | 音频输出 |
| GFX | Graphics Engine | Graphic Engine 提供对2D画图的基本硬件加速支援,降低CPU的负荷 |
| FB | FrameBuffer | UI显示 |
| HDMI | High Definition Multimedia Interface | HDMI/VGA标准输出 |
| AEC | Acoustic Echo Cancellation | 回声消除,抑制远程回声的算法 |
| AED | Acoustic Event Detection | 声学事件检测,用于在音讯码流中侦测特定的声音事件 |
| APC | Audio Process Chain | 音频处理链路,包含降噪、均衡器和自动增益控制的算法组合 |
| BF | beamforming | 波束形成或空间滤波,用于传感器数组的定向信号处理技术传输或接收 |
| SRC | Sample Rate Conversion | 重采样,用于对音频流做采样频率转换 |
| SSL | Sound Source Localization | 声源定位,用于定位声音来源的方向 |
| SENSOR | Sensor | 获取摄像头接口信息、调整分辨率和帧率等功能 |
| VIF | VIDEO Input Interface | BT656/BT1120/MIPI等信号采集单元 |
| ISP | Image Signal Processing | 实现 HDR,3D/2D 降噪,3A 算法,WDR 等相关功能 |
| IQSERVER | Image Quality tuning Server | 图像质量调校服务,用来完成调校工具(IQ Tool)和开发板之间的数据通信, 包括 ISP 参数设置,获取图像,上传/下载相关文件等功能 |
| RGN | Region | 区域管理模块,对SCL数据进行遮挡或叠加 |
| SED | Smart Encode | 智能编码,主要提供智能编码通道的创建和销毁、开启和停止检测源图像、计算结果并关联到指定的编码通道等功能 |
| IVE | Intelligent Video Engine | 提供图形智能识别算法中的基本算子支援 |
| VDF | Video Detection Framework | 整合各个视频算法识别库的中间件架构,包括MD/OD/VG |
| SHADOW | Shadow | 用来连接VDF user层的一个通道,如果要用VDF,则需要包含此模块(lib库和ko),无需实际调用shadow接口 |
| IPU | Intelligent Process Unit | 智能处理器,模块实现了AI 模型的推演功能加速 |
| CIPHER | Cipher | 提供数据的加解密功能,包括 AES\RSA\SHA 加解密算法 |
2. SDK软件架构¶
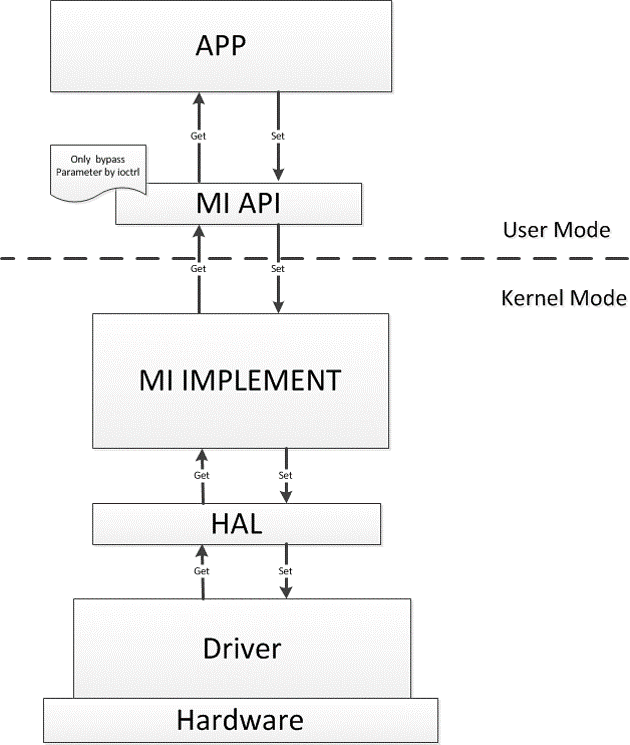
-
功能实现函数从上到下,分为MI API层,MI实现层,Hal硬件抽象层,Driver层和芯片硬件层。
-
MI IMPLEMENT和HAL层以ko形式给出,MI API以lib库的形式给出。
-
SDK功能代码在Kernel层实现,减少从kernel到User mode来回调度,提高逻辑函数实现的效率。
-
对上层客户提供MI API的User Mode接口,用户层APP直接调用MI接口,即可调用到对应的MI功能。
3. SDK目录结构¶
| 目录 | 模块名 | 功能 |
|---|---|---|
| project | board | PCB板信息存放路径 |
| configs | 预配置文件存放路径 | |
| image | 产生镜像文件的材料库和镜像文件存放处 | |
| kbuild | kernel编译环境 | |
| release | 目标池,存放对外头文件/文档/库文件和内核模块以及第三方库 | |
| scripts | 编译辅助功能脚本 | |
| tools | 一些通用工具 | |
| sdk | verify/xvr_demo | xvr/nvr的一些参考测试demo |
4. 内存管理¶
4.1. 内存分配方式¶
通过环境变量设置预留内存用量:
# cat /proc/cmdline ubi.mtd=ubia,2048 root=/dev/mtdblock5 rootfstype=squashfs ro init=/linuxrc LX_MEM=0x80000000 mma_heap=mma_heap_name0,miu=0,sz=0x40000000 mma_heap=mma_heap_fb,miu=0,sz=0x1000000 mma_memblock_remove=0 cma=2M mtdparts=nand0:1536k@1280k(BOOT),1536k(BOOT_BAK),256k(ENV),5m(KERNEL), 5m(RECOVERY),6m(rootfs),1m(MISC),109056k(ubia)
-
LX_MEM为总的DDR内存。
-
mma_heap=mma_heap_name0后的sz带的参数是预留给sdk编解码使用的总内存;大小需要根据产品规格评估。
-
mma_heap=mma_heap_fb后的sz带的参数是预留给FB模块使用的总内存。/misc/config.ini里面还会配置fb节点的内存(比如FB_BUFFER_LEN = 8192,单位为KB,则是给当前fb分配8M内存),如果有多个fb节点,则要各fb节点的内存相加等于这里的sz大小即可;如果是单fb节点,则fb节点内存与这里的sz预留大小相等即可。
5. 基本概念¶
-
数据流:各个MI Module 可以看成是一个纯数据处理单元,数据流推送由MI SYS内部统一调度。输入数据流表示该数据单元的input数据,输出数据流表示该处理单元处理过的output数据。
-
控制流:APP 对各个MI Module 数据处理过程进行参数控制的过程,比如设置MI_VDEC解码参数,启动停止MI_VDEC 通道,设置MI_VDEC通道输出端口之分辨率及format等
-
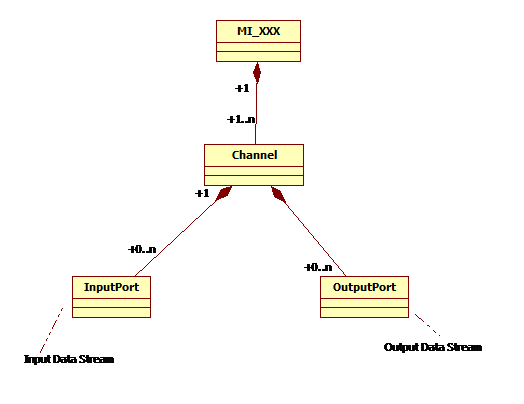
Channel(通道)
对于需要处理或者输出stream的MI模组,一个channel代表该MI 模组处理或者输出一路stream的分时复用的上下文(context)及相关控制流设定
对于可分时复用之模组如MI_VDEC, MI_DIVP, MI_DISP,可支援多个channel
-
Port(端口)
Port分为2种,input port和output port。input port为channel输入数据流的位置,而output port则是channel输出数据流的位置。
一个channel可以有多个input port及多个output port.
6. NVR&XVR架构¶
6.1. NVR&XVR软件架构¶
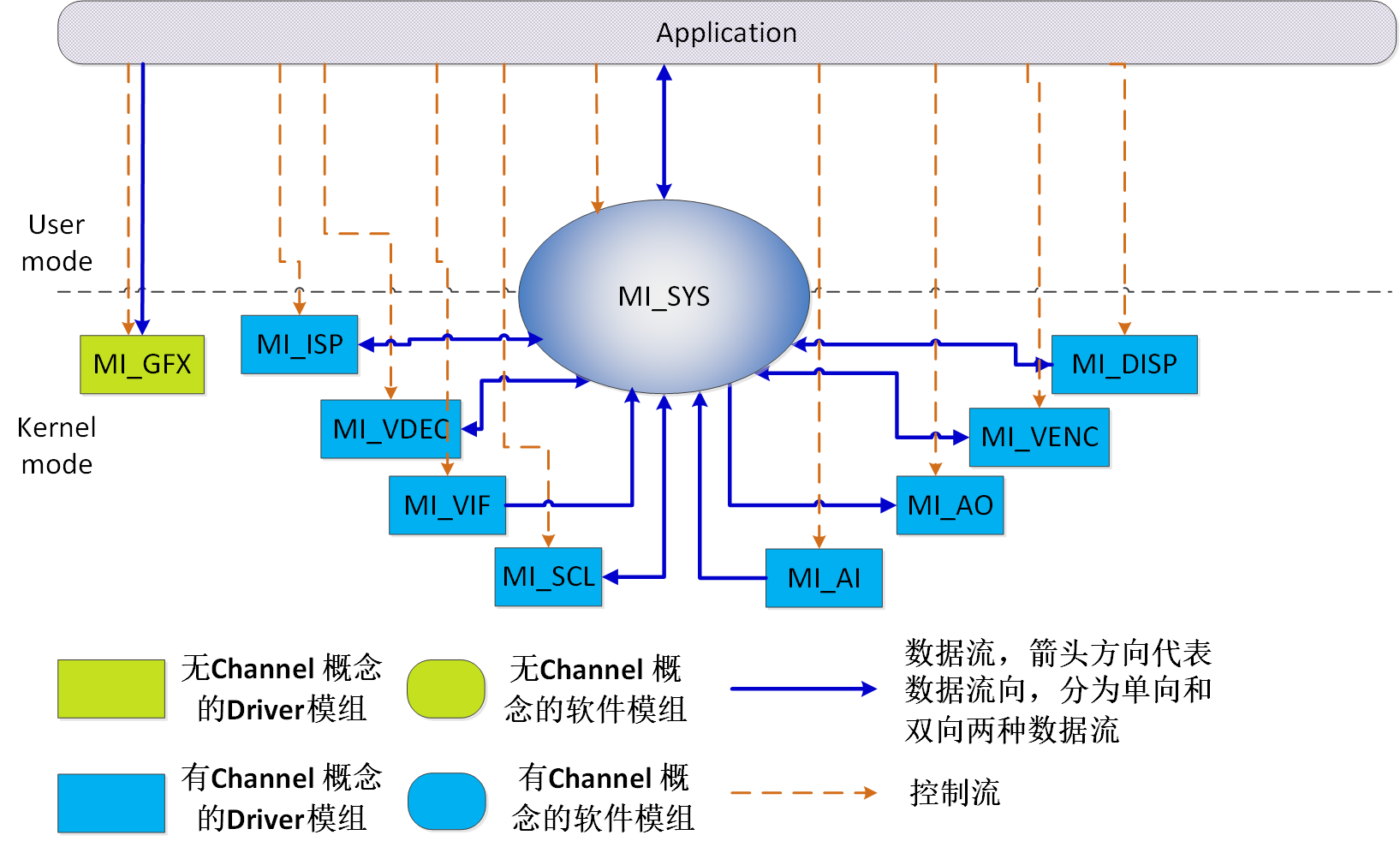
-
ai/ao/fb/gfx/hdmi都是相对独立的模块,不需要和其它模块串接。
-
nvr最重要的是解码显示流程,一般vdec->disp即可,某些流程还需要再串接一级scl,即vdec->scl->disp。
-
xvr主要包括回放流程(和nvr一致),预览流程(vif->isp->scl->disp)和存储流程(vif->isp->scl->venc)。
6.2. NVR常见数据流¶
6.2.1. 解码显示¶
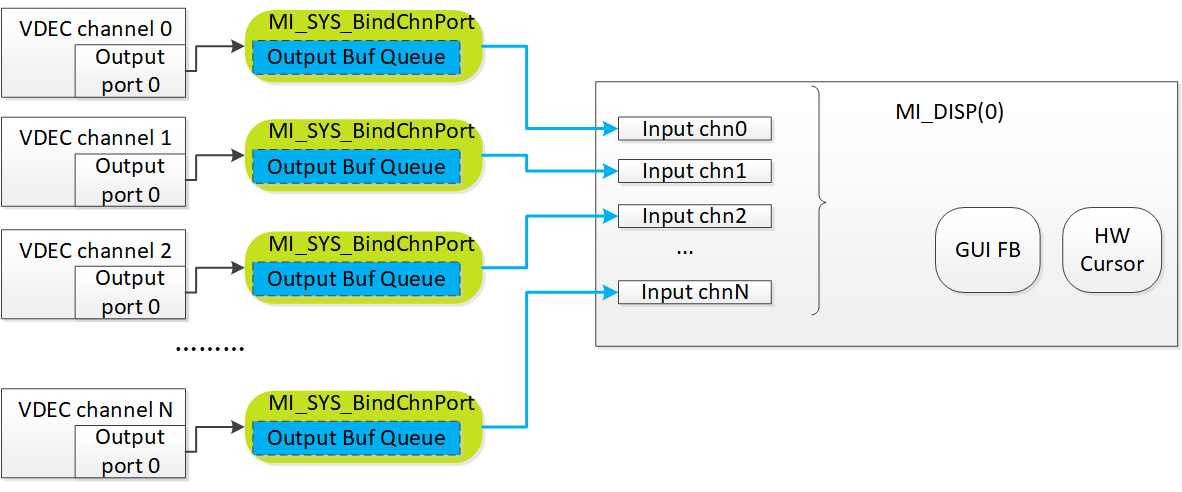
vdec channel只有output,disp channel只有input,一般解码显示只需要将vdec chn绑定到disp chn即可,port口都为0。
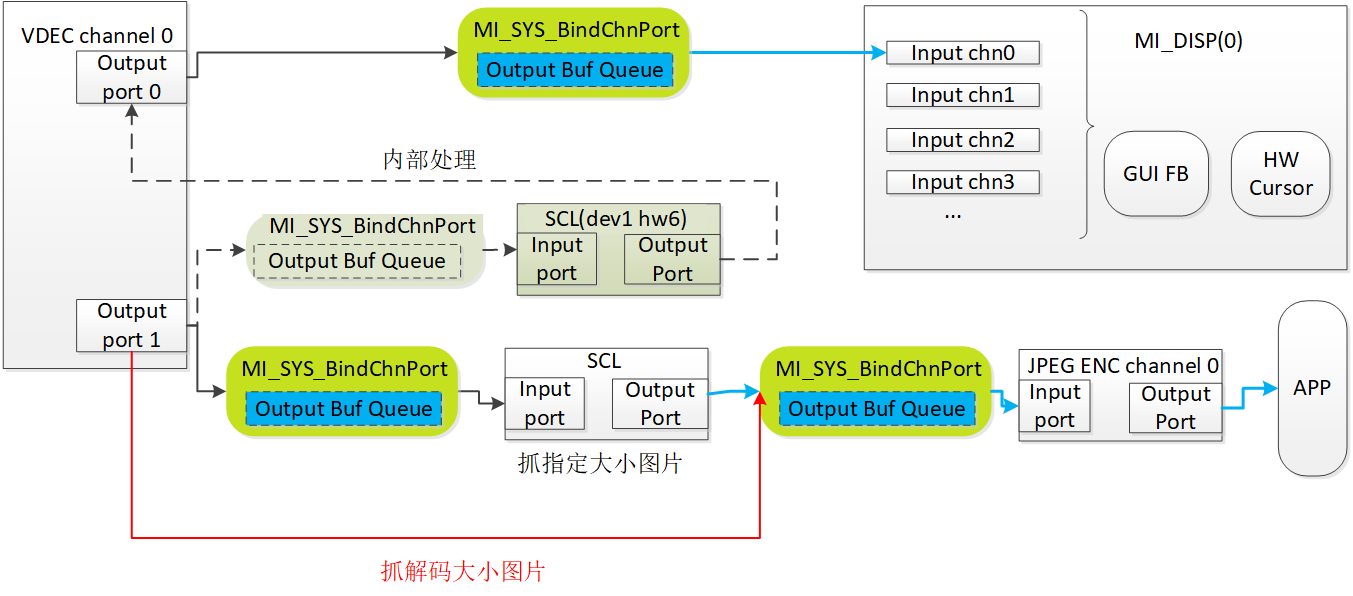
6.2.2. 抓图¶
-
由于vdec解码出来的图像往往是已经缩小到disp显示的size(比如16分屏下),不能满足原始size抓图的需求,为了满足这种需求,引入vdec port1概念。
-
默认会解码出原始size图像到port1,然后内部将port1(通过scl dev1 hw6)缩小到disp size到port0,port0再绑定disp去显示。
-
port1的数据可以直接用于抓图,如果抓原始size图片可以直接port1绑定到venc。
-
如果要抓指定size图片,可以将vdec port1先绑定一个scl(dev hw不限)做缩放,然后scl绑定venc编码成图片。
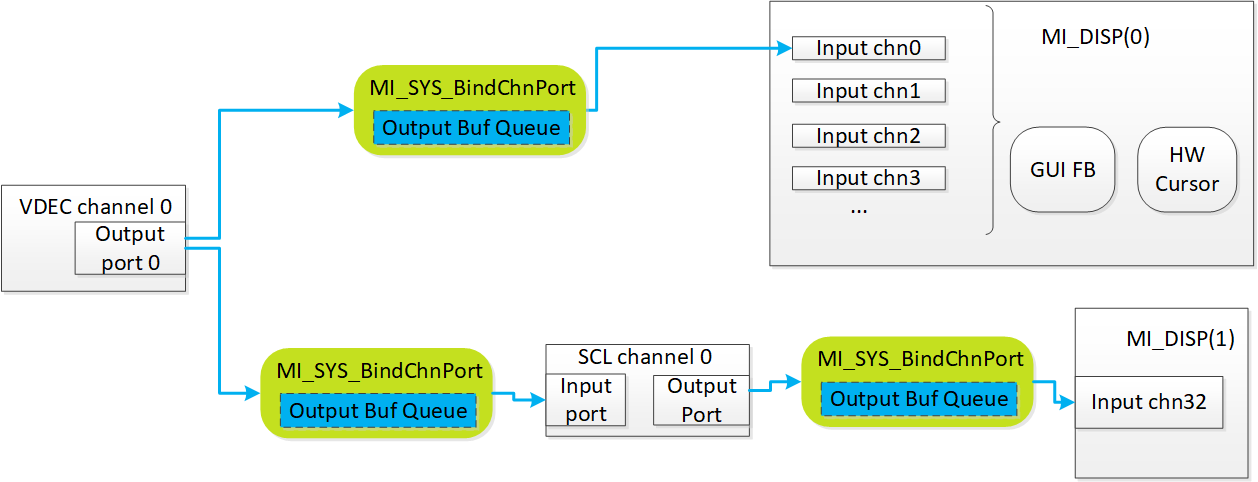
6.2.3. PIP¶
-
disp有四层layer,layer0 / 2有32个chn,layer1 / 3有1个chn,用于PIP显示,input通道号固定为32。
-
由于一般PIP窗口都比较小,所以会直接从vdec chn绑定scl做缩放,然后scl绑定pip disp显示。
-
layer1 / 3永远在layer0 / 2之上,UI之下。
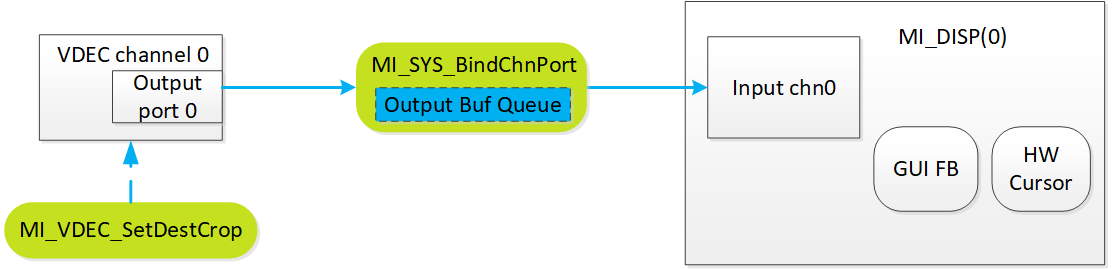
6.2.4. 电子放大¶
-
vdec,scl和disp模块都可以做crop,走scl模块则会多耗一级内存和带宽。
-
disp窗口小于vdec size的情况下,走disp crop则会对清晰度打折扣,所以nvr上只建议用vdec做crop。
6.3. XVR常见数据流¶
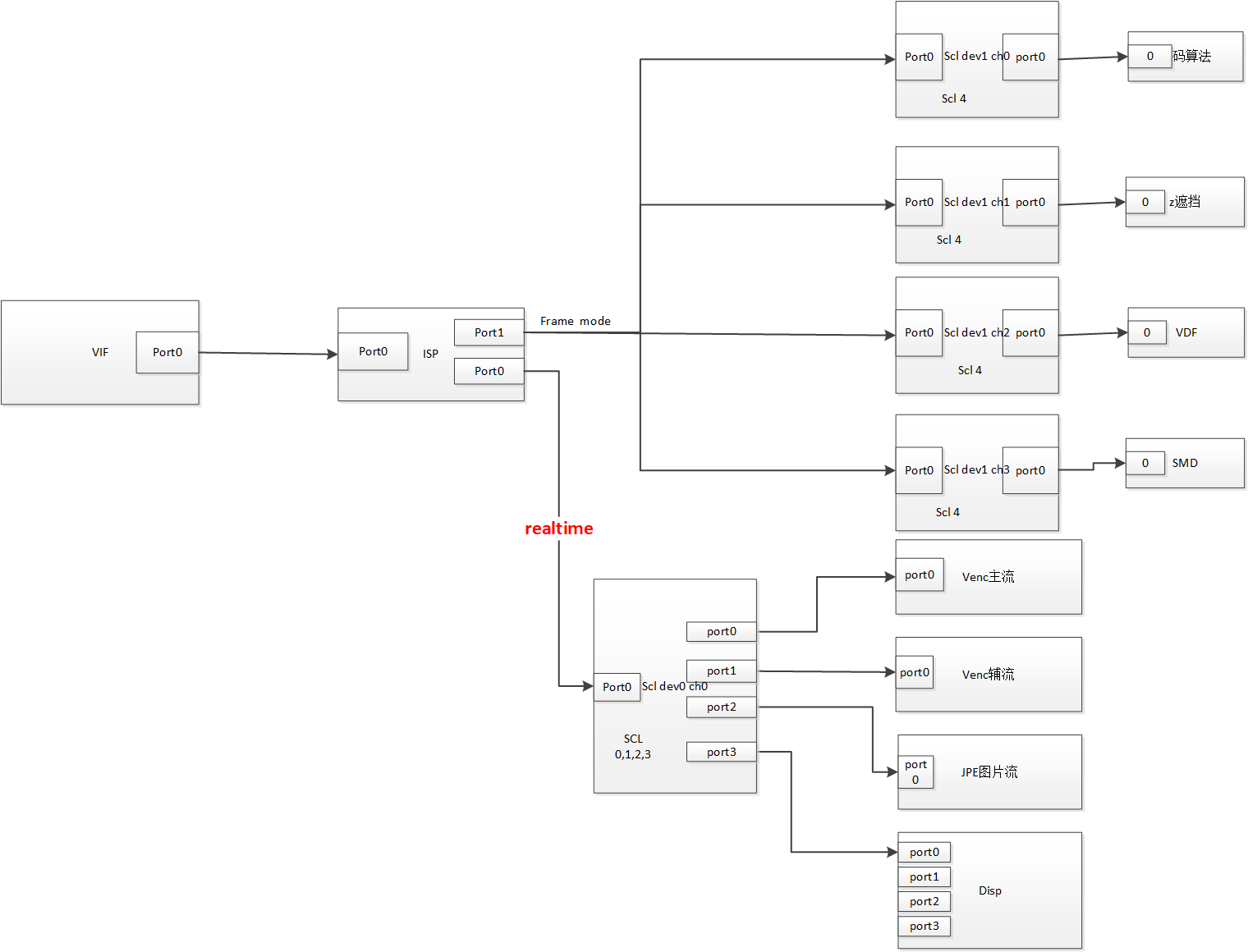
6.3.1. pipeline参考¶
模块串接可以有多种,有的更省频宽,有的更省内存,下图是推荐使用的pipeline(只列出其中1路vif->isp->scl->venc或disp的流程,其它路相同),已经是最节省内存的方案,而且用户层串接也相对比较简单,用户只需根据自己的实际场景做微调。
注意ISP和SCL绑定尽量使用realtime模式(ISP output port0),可以节省内存和带宽。在SCL硬件数量不够的情况下再考虑用framemode绑定(ISP output port1),尽量让分辨率低帧率低的流程走framemode。
6.3.2. 电子放大¶
xvr电子放大有2种,1种是回看电子放大,方案和nvr一样,vdec做crop即可。另一种是预览电子放大,流程是vif->isp->scl->disp,因为scl可能有多个output port,因此建议在scl的output做crop。