System
Q1: 当产品出现应用&系统异常时,该如何做异常保护机制?
-
一般在应用主进程搭建watchdog机制可以保证当应用和系统异常做reboot启动保护;
-
kernel将CONFIG_PANIC_TIMEOUT设置成非0,当panic时,会根据设定的值delay几秒后重启;
Q2: 如何在不接串口打印的情况下,定位死机问题?
-
应用层的段错误问题可以打开coredump,然后解析coredump来定位问题,打开coredump步骤如下:
-
在profile中增加如下内容:
ulimit -c unlimited echo "if [ -e /etc/core.sh ]; then" >> ${OUTPUTDIR}/rootfs/etc/profile echo ' echo "|/etc/core.sh %p" > /proc/sys/kernel/core_pattern' >> ${OUTPUTDIR}/rootfs/etc/profile echo "chmod 777 /etc/core.sh" >> ${OUTPUTDIR}/rootfs/etc/profile echo "fi;" >> ${OUTPUTDIR}/rootfs/etc/profile
-
在etc/core.sh中增加如下内容:
#!/bin/sh /bin/gzip -1 > /config/coredump.process_$1.gz -->定义产生coredump文件的路径,需可写,避免生成coredump失败;同时确认有gzip命令 sync
解析coredump方法如下:
-
gunzip coredump_xx.zip;
-
arm-linux-gnueabihf-gdb APP(生成coredump对应的应用app)
-
set solib-search-path ../../sdk/verify/application/zk_full/lib/ ( app链接对应的lib)
-
core-file coredump.process_xxx
-
bt
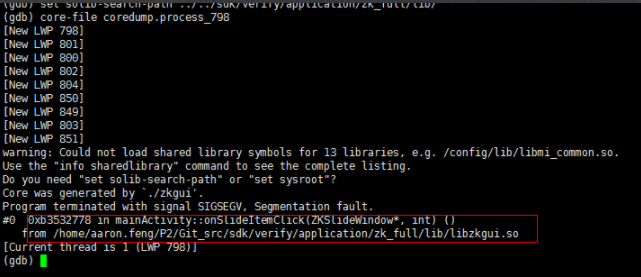
一般coredump机制只在开发阶段打开使用,量产阶段需要关闭,不然会撑爆flash分区,关闭时把上面步骤2中的内容删除即可。
-
-
-
kernel panic的log保存可以参考如下:
主要利用linux原生的CONFIG_MTD_OOPS机制,通过kmsg_dump_register注册对应flash的mtdoops_do_dump函数,在kernel发生OOPS或者panic时会调用mtdoops_do_dump将kmsg信息写入到对应的mtd分区,实现保存重启前kernel异常log的功能。
主要改动如下:
-
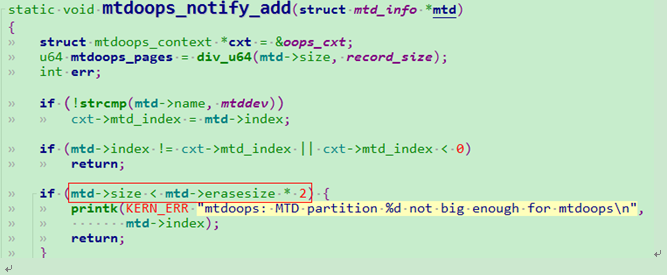
在flash分区时,新建128KB kmsglog分区用于保存panic 异常log(记住kmsglog分区对应的/dev/mtdblocknum,后面通过cat该节点查看kmsg内容)
注意:新建分区size必须不小于对应flash的erasesize*2,否则insmod mtdoops会报错。
-
kernel主要改动如下:
-
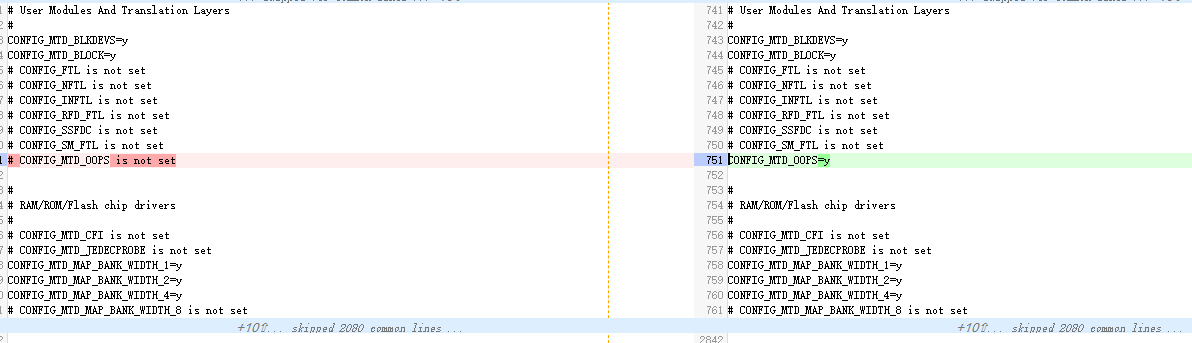
打开CONFIG_MTD_OOPS,并设置保存对应kmsg的mtd分区;
-
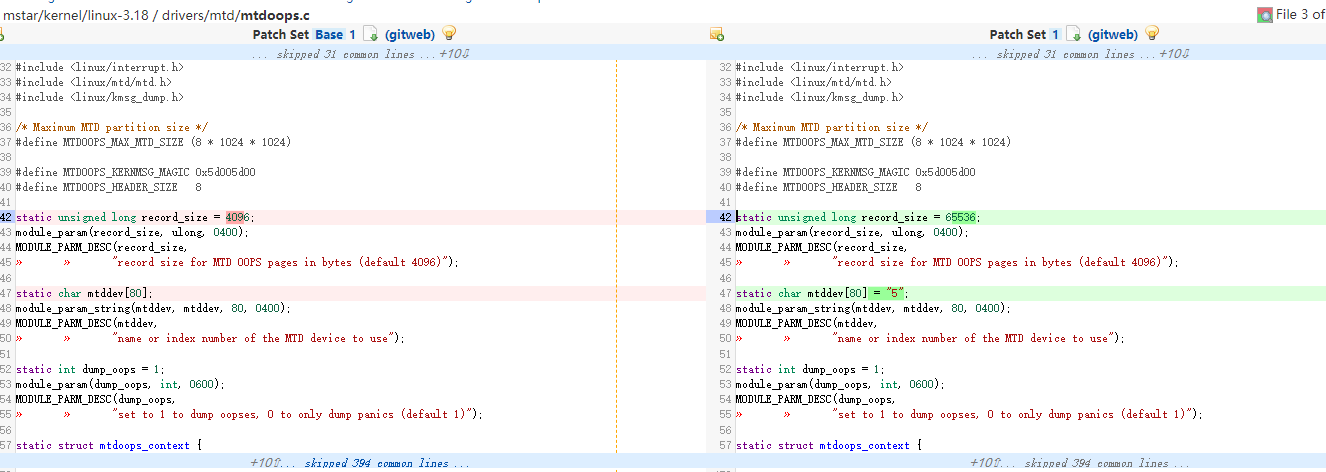
根据实际情况设置需要保存kmsg的缓冲区大小record_size,一般设置64K就足够了。因为保存kmsg缓冲区的时候是从打印panic log的位置开始往上算64K的大小,一般backtrace都不会大于64K;
-
目前是在设定的mtd分区大小内循环保存kmsg信息的,比如现在保存的kmsg大小是64K,mtd大小是128K,那么总共只能保存两次kernel panic的log,超过两次时会覆盖第一次保存的kmsg信息。
-
实现kmsg注册的mtdoops_do_dump内的写flash函数,一般用flash对应的write函数即可;
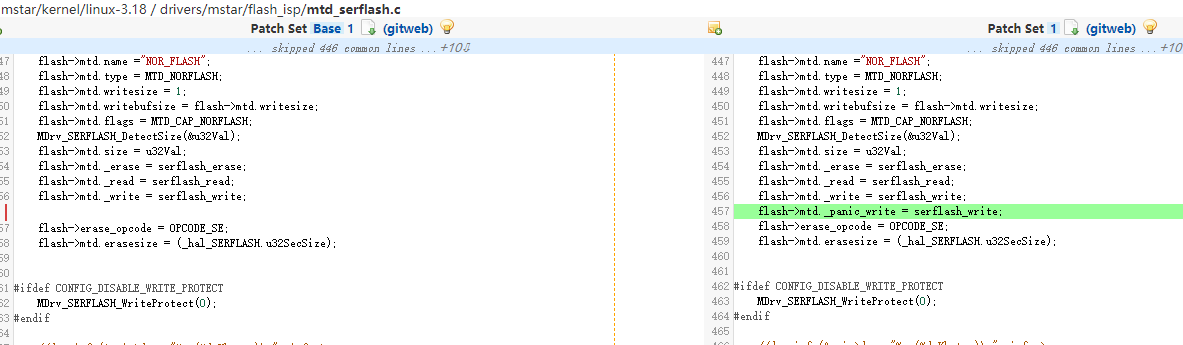
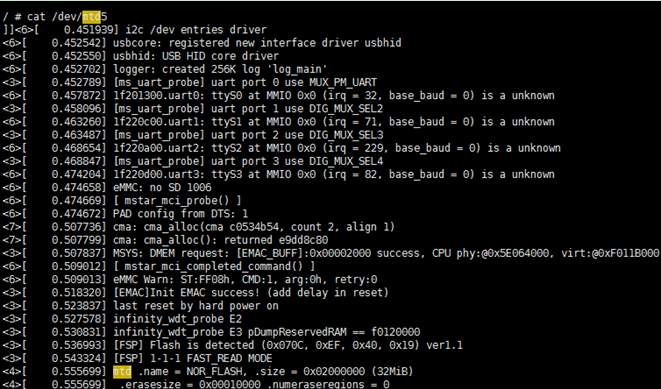
使用方法:
Cat 新建kmsglog分区对应的/dev/mtdblocknum,或者重定向到文件保存。
-
-
...