RTK
1. 概述¶
RTK全称Real Time Kernel。它是一个多任务,基于优先级调度服务的系统。它提供临界段代码管理(critical section management),通过semaphore, mutex, flag, timer来实现各任务间的通讯和同步。
2. 系统初始化¶

图 2‑1 RTK系统初始化
3. 任务(task)¶
RTK Task中,Priority 0为最低优先级。在SDK中被定义为TASK_IDLE_PRIO。
设定为高优先级的任务,必须保证其执行时间越短越好。耗时的部分,需要拉到低优先级去做,避免低优先级的任务被卡死而导致系统不正常。
不要创建相同优先级的任务。
3.1. 系统任务¶
系统任务优先级最高为50,最低为0。(新SDK 更新到54 - 0)

图 3‑1 系统任务优先级
系统任务放在cus_InitTask[]中,开机时由RtkCreateSystemTask创建。
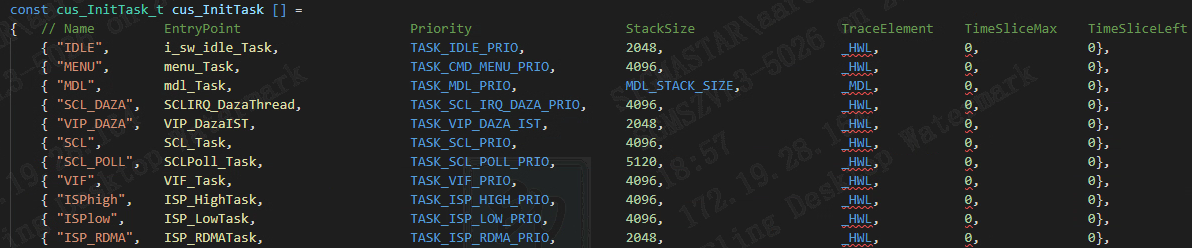
图 3‑2 新建系统任务
除了TASK_IDLE_PRIO,其它系统任务优先级必须超过自定义优先级。软件中我们会对系统任务优先级作一个偏移。

图 3‑3 系统任务优先级偏移
3.2. 自定义任务¶
自定义任务优先级最高为200,最低为1。任务由AHC_OS_CreateTask()创建。
3.2.1. 任务状态机¶

图 3‑4 任务状态
当某个任务状态满足 "(state & RTK_NON_OPERATIONAL) = RTK_READY" 条件时,意味该任务现在可以被调度,无需等待其它额外事件。
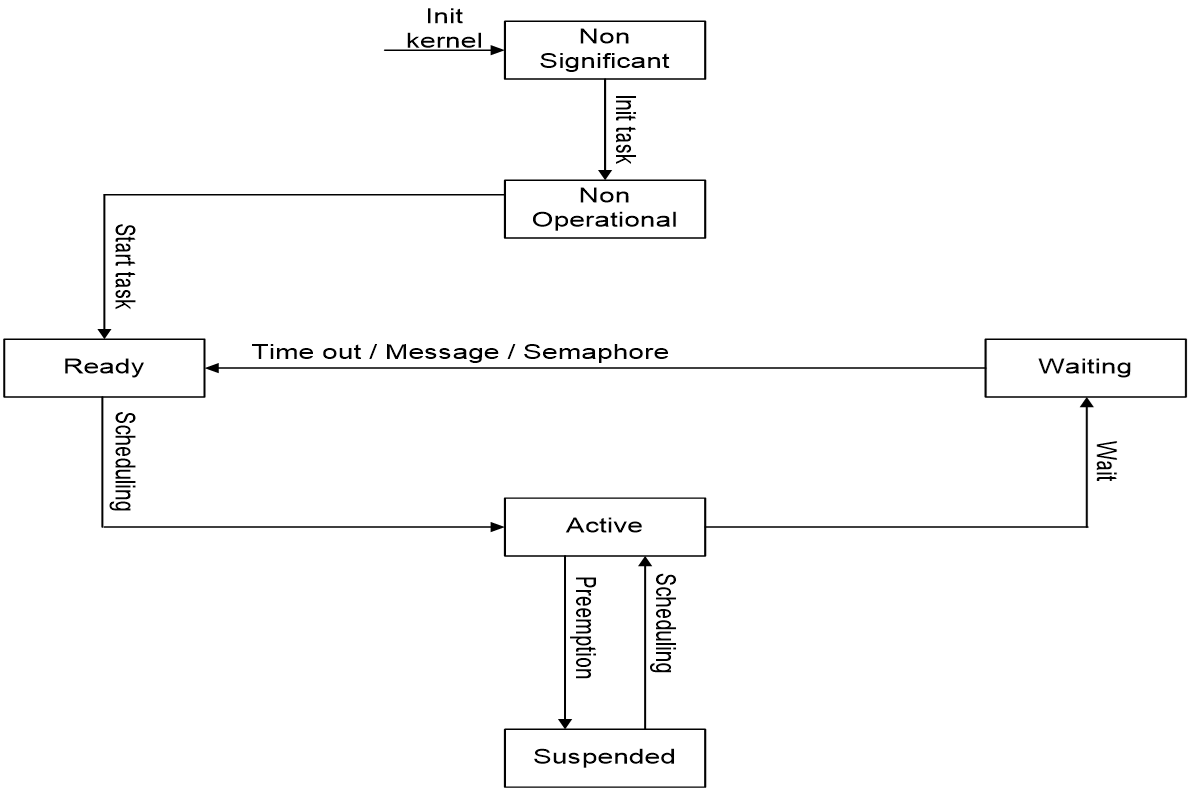
图 3‑5 任务状态
3.2.2. 调度方案¶
-
多级队列调度
-
抢占式,基于优先级
-
相同优先级任务,先准备好的先处理

图 3‑6 调度方案
4. 临界段代码管理(Critical Section)¶
-
MsEnterRegion() / MsLeaveRegion()
-
任务能够被中断但是不可以被抢占
-
由Rtk_RegionCount计数器控制,0 \<= Rtk_RegionCount \<= 255
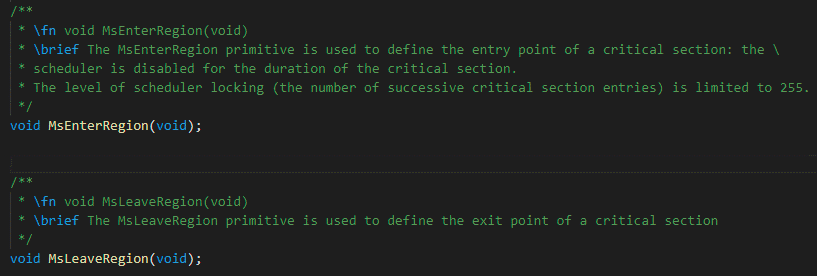
图 4‑1 临界段代码管理1
-
-
MsEnableInterruptUser() / MsDisableInterruptUser()
-
User mode中断获取锁
-
操作INTC(System Interrupt Controller)掩码
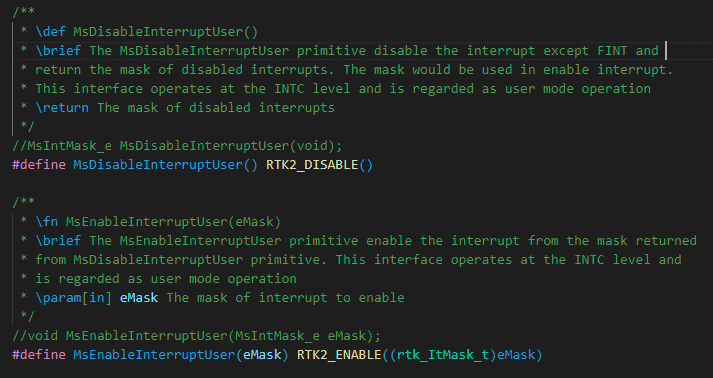
图 4‑2 临界段代码管理2
-
-
MsEnableInterrupt() / MsDisableInterrupt()
-
Kernel mode 中断获取锁
-
操作ARM CPSR IRQ 位
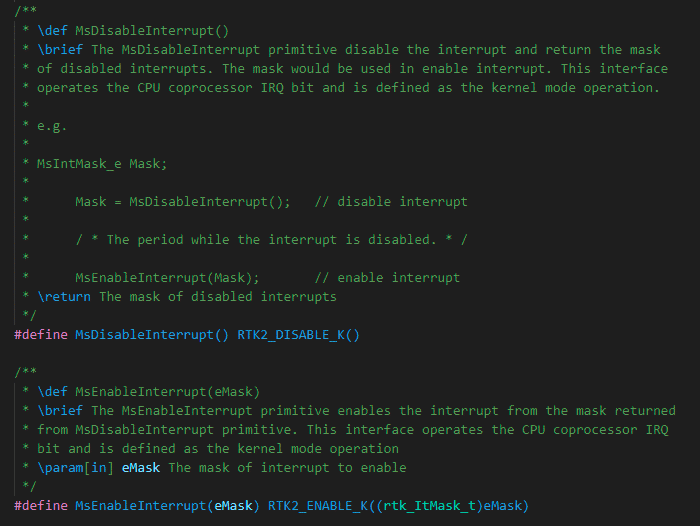
图 4‑3 临界段代码管理3
-
5. 信号量(Semaphore)¶
-
Semaphore通常用在任务同步,临界段代码管理,事件通知等情况
-
每一个semaphore包含一个令牌(token)和一个任务队列(task queue)
-
等待中的任务按照优先级顺序激活
-
Semaphore必须在启动任务时创建
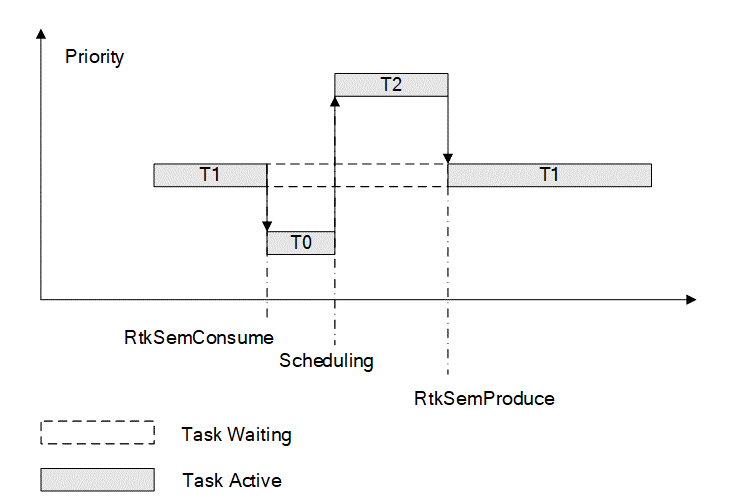
图 5‑1 任务优先级
6. 互斥(Mutual Exclusion Object)¶
-
通常用于保护关键区域的访问
-
等待中的任务按照优先级顺序激活
-
Mutex 必须在启动任务时创建
-
Mutex 必须要由获得锁的任务来释放
-
支持优先级继承协议
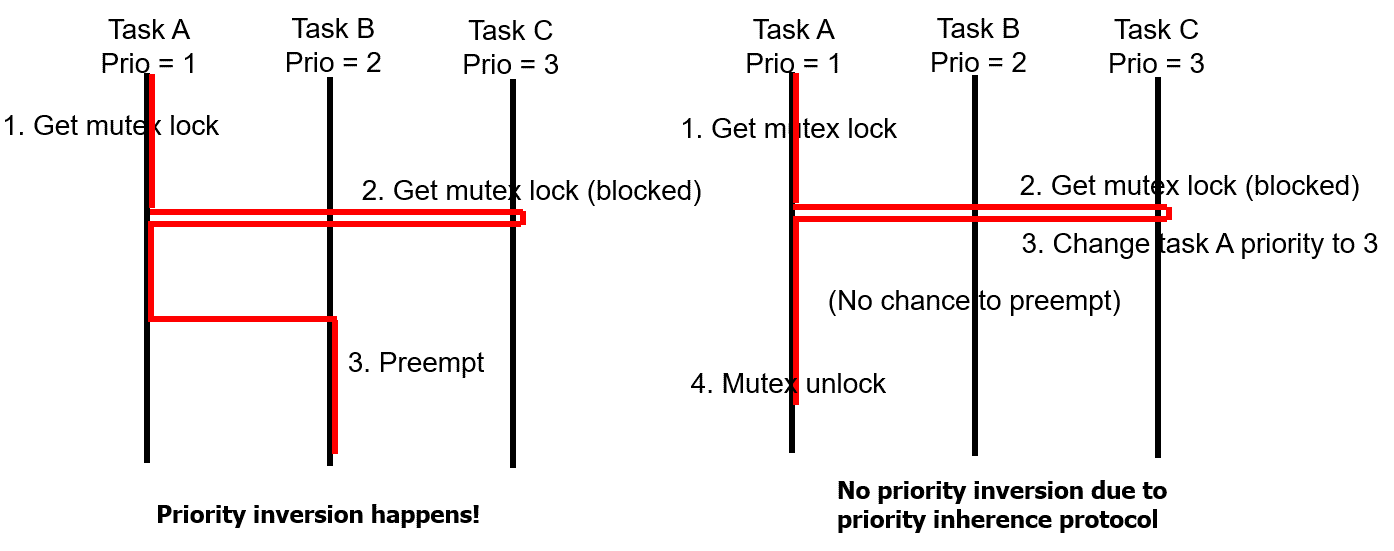
图 6‑1 优先级继承
7. 标志(Flag)¶
-
Flag是由一个字(word)32位(bits)数据表示的任务同步机制
-
Flag中的每一位表示一个条件,而线程在等待单个条件或条件组合被满足
-
当规定的所有条件或者条件组合满足时,等待中的线程将会被唤醒
-
信令线程可以根据特定条件设置或重置位,以便执行适当的线程
-
Flags可以在应用程序运行时随时创建
8. 中断¶
-
只有一级中断服务程序
-
所有的RTK 服务都允许中断
9. 定时器¶
-
支持两类定时器服务
-
消息类型
在接收任务解析器中完成
-
回调类型
在最高定时器任务中完成
必须避免复杂的处理程序
-
-
时钟精度为4.6 毫秒
-
支持一次性和周期性计时
10. 内存¶
10.1.1. Pool和Heap的区别¶
-
两种类型的动态内存管理
-
固定大小: pool
-
可变大小: heap
-
-
Pool
-
可以调整内存池和簇数量
-
从Heap中获取空间并在启动时创建
-
速度快,没有碎片,但灵活性低(适合实时)
-
-
Heap
-
Heap大小等于 "total physical ram" 减去"static memory"
-
Validated GKI algorithm to achieve defragmentation
-
每个Block需要32字节对齐。
-
RTK heap 比较低效,它总是从heap 顶端开始线性查找第一个合适的可用内存。
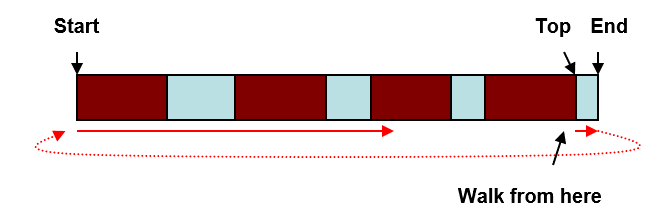
图 10‑1 RTK系统Heap
-
-
一般的malloc调用
-
8x39目前只用"heap"。
-
Malloc的地址需要对齐,比如32字节。
-
11. Cache和 Non Cache¶
RTK中,当CPU要写东西到DRAM时,会先进入Write Buffer,而不是直接进DRAM的物理地址。就算用的Buffer是Non Cache也一样。
例如,
-
UI画图 --DRAM,GOP ENGINE拿DRAM叠图。图画完时,物理内存内的数据可能还没有更新。
-
CPU写I2C的命令进DRAM,透过I2C DMA去拿DRAM数据,物理内存内的数据可能还没有更新。
这个时候需要调用下面函数去刷掉(Flush) Write Buffer,避免出现问题。
DrvChipFlushMiuPipe()
即当我们通过CPU向DRAM存取数据,然后又需要HW ENGINE去存取DRAM中的这一些数据时,就需要调用上面的函数。
注:RIU (register fifo)模式不包括在内。
12. RTK内存分配¶
12.1. RTK中存储管理单元(MMU)设定¶
0x20000000 ~ 0x28000000 属于CACHE //833x
0x90000000 ~ 0x98000000 属于NON CACHE
12.2. 内存分配函数¶

图 12‑1 内存分配函数
在图12-1中,ppUserPtr为虚拟地址,CPU 读写或memset / memcpy都是用这个地址。pMiuAddr为MIU地址,HW ENGINE使用这个地址。

图 12‑2 虚拟地址和物理地址互转

图 12‑3 物理地址转为MIU地址