板端使用问题
在板上运行网络模型输出数据怎么和PC上不一样?
首先需要明确一点Fixed和Offline模型在PC上和板上运行时,给定相同的输入,输出的有效数据一定是一样的。使用以下方法,可以验证: 在PC上仿真,使用simulator.py运行Fixed或Offline模型时加上参数--dump_rawdata,运行结束后会在当前路径下保存一个图片名+ .bin的文件。该文件是在PC上做过前处理的输入数据,以二进制文件形式保存下来。在板端读取该文件,将该文件内所有数据memcpy到模型的输入Tensor,然后执行MI_IPU_Invoke。得到的输出和在PC上应该是完全一致的。
在板上运行网络模型输出数据维度怎么不一样?
如果转换网络时input_config.ini中dequantizations设为FALSE,Fixed和Offline模型运行完成后,输出数据的最后维度会向上对齐。由于硬件的写数据原则导致,因此无论在PC上仿真还是在板上实际运行,都会有这个现象。使用simulator.py时,-c设Unknown,输出文件中会有如下提示:
layer46-conv Tensor:
{
tensor dim:4, Original shape:[1 13 13 255], Alignment shape:[1 13 13 256]
The following tensor data shape is alignment shape.
tensor data:
...
其中Alignment shape是模型真正输出的数据维度。 使用calibrator_custom.fixed_simulator创建Fixed模型的实例,完成invoke后,调用get_output方法得到result的 numpy.ndarray数据shape也会有对齐。
>>> print(result.shape)
(1, 13, 13, 256)
具体详见5.2.1节去除无用数据。
板上运行的输出是浮点还是定点?
板上运行的结果与网络转换时input_config.ini配置相关。当dequantizations配置为TRUE时,在板上对应Tensor输出为浮点数据。另外还可以通过MI_IPU_GetInOutTensorDesc接口查看输出Tensor的数据类型。
运行时,模型占用的内存如何查看?
cat /proc/mi_modules/mi_ipu/mi_ipu0参看以下解释
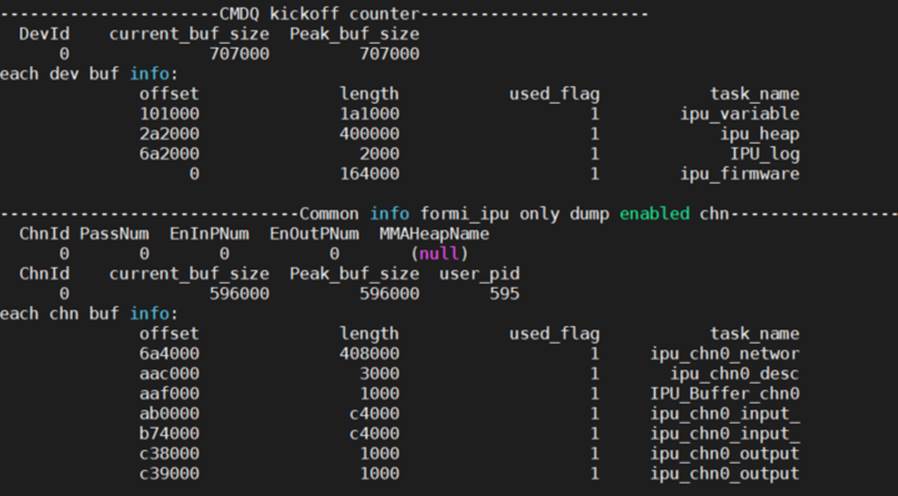
ipu_variable:所有网络模型推理过程中临时使用的内存
ipu_heap:ipu firmware中malloc使用的堆
IPU_log:存储log使用的内存
ipu_firmware:ipu firmware运行占用的内存
ipu_chn0_networ:channel 0装载网络模型使用的内存
ipu_chn0_desc:channel 0的网络描述占用的内存
IPU_Buffer_chn0:channel 0临时占用的内存
ipu_chn0_input_:channel 0 输入tensor占用的内存(多个则代表有多个输入tensor可同时使用)
ipu_chn0_output:channel 0输出tensor占用的内存(多个则代表有多个输出tensor可同时使用)